
SPARK共8篇
排序
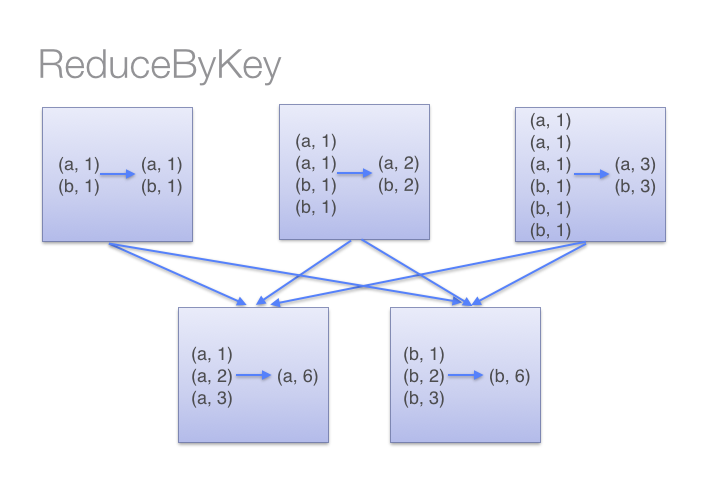
Spark中reduceByKey和groupByKey的区别
方法定义: 1.reduceByKey(func[,num Tasks]) 当键值相同的键值对(K,V)数据集调用此方法,他们的键对应的值会根据指定的函数(func)进行聚合,而键值(V,V)也进行合并,返回键值(V),最终返回一个...

Spark三种部署方式比较
目前Apache Spark支持三种分布式部署方式,分别是standalone、spark on mesos和 spark on YARN,其中,第一种类似于MapReduce 1.0所采用的模式,内部实现了容错性和资源管理,后两种则是未来发...
Spark配置参数
以下是整理的Spark中的一些配置参数,官方文档请参考Spark Configuration。 Spark提供三个位置用来配置系统: Spark属性:控制大部分的应用程序参数,可以用SparkConf对象或者Java系统属性设置...

Spark提交任务显示waiting状态解决办法
在使用Spark执行任务时,如果是同时提交多个任务,然后通过端口18080查看任务的状态会发现有的任务的状态为waiting状态,控制台提示:Initial job has not accepted any resources; check your ...
使用Idea在Windows上开发spark程序
环境搭建 由于平时开发工作主要在windows平台进行,所以在Windows平台搭建spark开发环境很有必要,在开始进行程序开发之前你可能需要参考以下文章: 在Windows平台安装Hadoop(不借助cygwin); ...
在Windows上运行Apache Spark
这篇文章介绍如何在Windows上运行Apache Spark 。 一、环境要求 运行spark需要以下条件的支持: Java6+ Scala 2.10.x Hadoop 2.7.x 二、安装步骤 安装Jdk 7 或更高版本,设置Java_Home和Path环...
Spark中mapToPair和flatMapToPair的区别
本文介绍了Spark中mapToPair和flatMapToPair的区别。 函数原型 1.JavaPairRDD<K2,V2> mapToPair(PairFunction<T,K2,V2> f) 此函数会对一个RDD中的每个元素调用f函数,其中原来RDD中的每一...

Spark中map和flatMap的区别详解
本文介绍了Spark中map(func)和flatMap(func)这两个函数的区别及具体使用。 函数原型 1.map(func) 将原数据的每个元素传给函数func进行格式化,返回一个新的分布式数据集。(原文:Return a new d...